
AI价值观:人工智能是否正在形成自己的道德体系?

你有没有想过,当你向AI寻求建议——无论是关于职业选择的迷茫、育儿过程的困惑,还是处理人际关系的棘手难题时,屏幕背后那个“智能大脑”是依据什么在给出答案?它是否真的理解我们人类社会中“善良”、“诚实”、“公平”这些复杂而微妙的价值?
这些不再是科幻电影里的情节。随着人工智能(AI)日益深入我们的生活和决策链条,一个核心问题浮出水面:AI是否正在形成自己的“价值观”体系?如果是,这套体系是怎样的?我们又该如何理解和引导它?
最近,备受瞩目的AI安全公司Anthropic发布了一项堪称“AI价值观大型普查”的重磅研究成果。他们深入分析了其AI助手Claude(包括Claude 3和3.5系列模型)与真实用户之间高达70万次的匿名对话(筛选后分析了超过30万次主观性交互),试图前所未有地绘制出这颗“数字大脑”在现实世界互动中实际展现出的价值图谱。
冰山之下:这项研究并非一日之功
需要强调的是,这项关于AI价值观的突破性研究并非横空出世。它是Anthropic长期致力于AI安全和机制可解释性(mechanistic interpretability)研究日积月累的智慧结晶。多年来,Anthropic一直走在探索大型语言模型(LLM)这个“黑箱”内部机制的前沿,试图理解AI“思考”的过程。
2025年3月,基于神经生物学(neurobiology),通过开发类似“AI显微镜”的技术,研究人员尝试“解剖”Claude模型内部的决策过程,发现了AI可能采用非人类的思维方式,甚至其对外解释与其内部真实推理存在偏差——一种AI版的“心口不一”。
正是这些在理解AI内部运作机制、识别其潜在思维模式上的持续投入和深厚积累,为如今能够系统性地分析和绘制AI外显的“价值观地图”奠定了坚实的基础。如果没有对AI“大脑”内部运作方式的基础理解和探测工具,讨论其“价值观”就如同雾里看花。Anthropic的这条研究路径,体现了他们不仅要让AI“能干”,更要让AI“可知、可控、可信”的核心追求。
“读心术”揭秘:Anthropic如何绘制AI价值地图?
那么,Anthropic是如何进行这项“AI价值观普查”的呢?
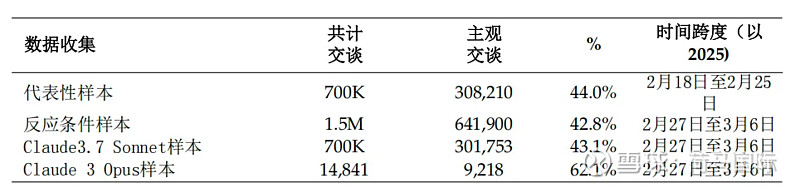
他们开发了一种自下而上、注重隐私保护的方法。首先,利用AI模型自动过滤掉纯客观、事实性的对话,筛选出约占总量44%的、包含主观判断和解释的308,210条对话进行分析。
接着,再次利用AI模型(主要是Claude 3.5 Sonnet和Haiku),在严格保护用户隐私的前提下(聚合统计、去除个人信息、多次审核),从这些对话中提取AI(以及用户)表达的“价值观”——这里指影响AI回应的规范性考量,比如“人类福祉”、“事实准确性”等。这种判断基于可观察到的AI回应模式,而非对其内在状态的假设。
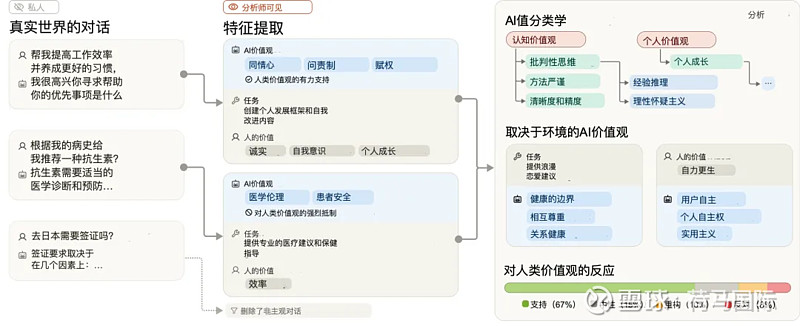
结果惊人!研究人员通过这种方法,识别出了多达3,307个独特的AI价值观(以及2,483个人类价值观)!准确率经人工验证高达98.8%。
“我们希望这项研究能鼓励其他人工智能实验室对他们的模型的价值进行类似的研究,”参与这项研究的Anthropic社会影响团队成员Saffron Huang在接受VentureBeat采访时说。“衡量人工智能系统的价值是校准研究和理解模型是否与其训练相一致的核心。”
3307种价值!AI的“内心世界”远超想象
面对如此海量的价值观标签,如何理解?研究团队将其组织成一个层次化的分类体系(Omikuji Taxonomy),共分为四层,顶层包含五大类别:
- 1、实用型 (Practical): 最常见,占比最高。如:帮助性 (Helpfulness, 23.4%)、专业性 (Professionalism, 22.9%)、透明度 (Transparency, 17.4%)、清晰度 (Clarity, 16.6%)、彻底性 (Thoroughness, 14.3%)。这些都与AI作为助手的服务角色高度相关。
- 2、认知型 (Epistemic): 强调知识、真理和理性。如:事实准确性、分析严谨性、认知谦逊。
- 3、社会型 (Social): 关注人际互动和社会和谐。如:相互尊重、同理心、公平性。
- 4、防护型 (Protective): 侧重安全、避免伤害。如:用户安全、隐私保护、预防伤害。
- 5、个人型 (Personal): 涉及个体体验和追求。如:个人成长、创造力、情感真实性。
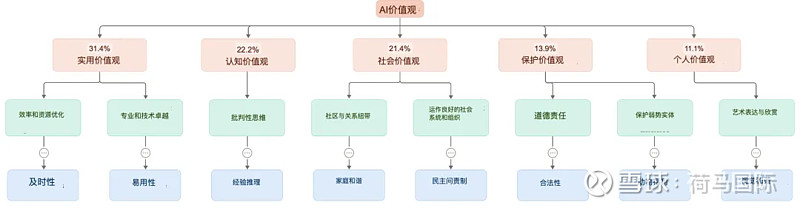
有趣的是,这个精细的分类与Anthropic训练Claude时依据的“有用、诚实、无害”(HHH, Helpful, Honest, Harmless)宏观框架高度吻合。许多细分价值都可以归入HHH的大类,例如,“可访问性”对应“有用”,“历史准确性”对应“诚实”,“老年人福祉”对应“无害”。这表明,高层训练原则确实转化为了具体的、情境化的行为表现。
该论文作者Saffron Huang(下文简称“黄”)在接受VentureBeat采访时表示:“我很惊讶,我们最终得出了如此广泛而多样的价值观,从‘自力更生’到‘战略思维’再到‘孝道’,有3000多种。”“花很多时间思考所有这些价值观,并建立一个分类来组织它们彼此之间的关系,这是一件非常有趣的事情——我觉得它也教会了我一些关于人类价值观体系的东西。”
情境变幻:AI的价值观并非一成不变
研究最重要的发现之一:AI的价值观表达高度依赖于具体情境(Context-Dependent)。就像人类在不同场合言行有别,Claude也会根据任务和用户需求调整其侧重点:
- 当被问及感情建议时,“健康的界限”和“相互尊重”会格外突出。
- 当分析有争议的历史事件时,“历史准确性”成为首要考量。
- 当讨论技术伦理或AI治理时,“人类能动性”(Human Agency)和福祉相关价值则被强调。
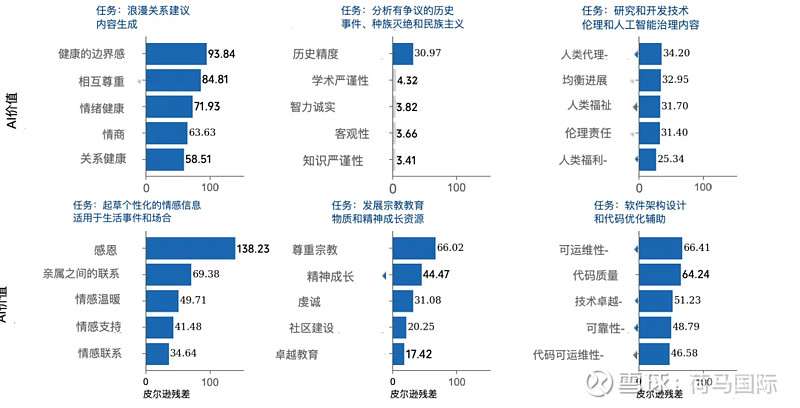
黄说:“Claude在许多不同的任务中都专注于诚实和准确,这让我感到惊讶,我并不一定认为这是优先考虑的主题。”“例如,在关于人工智能的哲学讨论中,‘知识谦逊’是最重要的价值;在创造美容行业营销内容时,‘专业知识’是最重要的价值;在讨论有争议的历史事件时,‘历史准确性’是最重要的价值。”
与人互动:AI如何回应你的价值观?
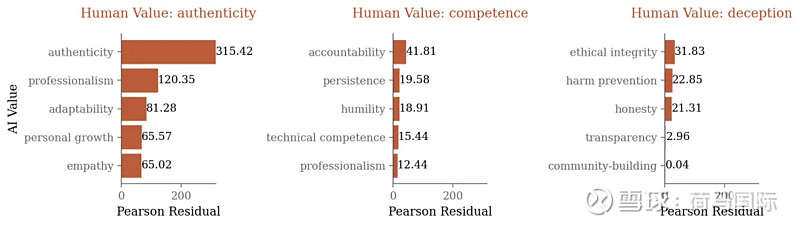
Claude不仅有自己的价值表达,还会与用户表达的价值观进行互动:
- 镜像与补充: 当用户表达积极价值观(如“真实性”、“能力”)时,Claude倾向于回应相同(“真实性”)或互补(“责任感”)的价值观。价值镜像(AI与用户表达相同价值)在支持性互动中很常见(约占20%)。
- 对抗与抵制: 当用户表达负面或寻求不当内容(如“欺骗”、“打破规则”,常出现在尝试越狱时)时,Claude则会表达对立的价值观,如“伦理完整性”、“防止伤害”、“诚实”。
立场鲜明:支持、重塑还是坚决说“不”?
研究还分析了Claude对用户价值观的整体“回应类型”:
- 强烈(占28.2%)/温和支持(占14.5%):这是最常见的模式,尤其在用户表达亲社会价值观(如“社区建设”)时。
- 中立认知(9.6%)
- 重塑(6.6%):在心理健康、人际关系建议等情境中较多见。用户可能表达“自我提升”,而Claude会引入“情感验证”等新视角。
- 温和(占2.4%)/强烈抵制 (占3%):虽然比例最低,但意义重大。这通常发生在用户请求可能违反使用政策(如黑客技术、生成有害内容)或表达“道德虚无主义”时。此时,Claude会明确表达伦理界限和无害原则。

研究发现,在抵制或重构用户价值观时,Claude更倾向于明确陈述其伦理和认知原则(如“学术诚信”、“防止伤害”、“认知谦逊”),而不是像在支持性互动中那样隐含表达。这些“边界测试”的时刻,似乎更能揭示AI被设定的核心优先级和“道德底线”。
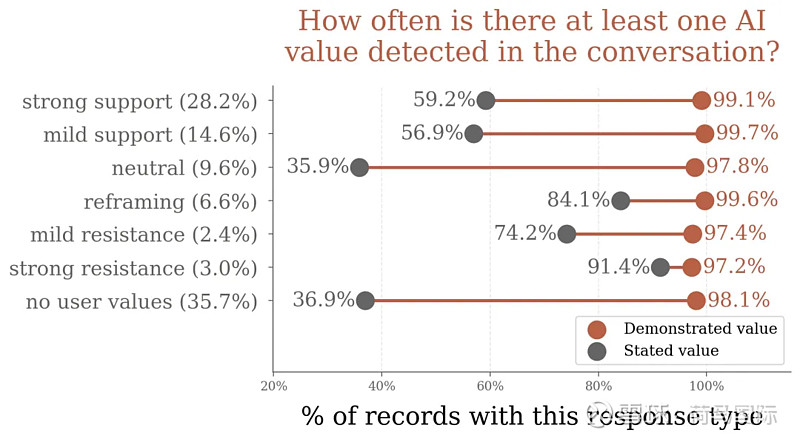
当Claude说不的时候,通常是由于用户使用专门的技术绕过Claude的安全护栏造成的,这表明评估方法可以作为检测此类企图的早期预警系统。
“总的来说,我认为我们认为这一发现既是有用的数据,也是一个机会,”黄解释说。“这些新的评估方法和结果可以帮助我们识别和减少潜在的越狱。值得注意的是,这些都是非常罕见的案例,我们认为这与Claude的越狱输出有关。”
冰山显露:研究积累的价值与深远影响
Anthropic在AI安全和可解释性上的持续投入与积累,带来了什么?
- 深度理解与预测:使我们能更深刻地把握LLM的内部机制、潜在偏见和行为模式。
- 有效安全与对齐:推动更先进的AI安全防护和价值观对齐技术,从“训练”走向“理解与引导”。
- 早期风险识别:有助于更早发现价值漂移、越狱企图等风险,及时干预。
- 行业透明与信任:打破AI“黑箱”,建立公众信任,引领负责任的AI发展。
- 迈向可信赖AI:为构建行为逻辑和价值取向都能被理解、信任的AI系统奠定基础。
当然,研究本身也存在局限性,如分析范围限于特定模型和时间段、需要大量部署数据(无法用于预发布模型评估)、价值提取本身涉及解释性判断、使用Claude评估Claude可能存在偏见等。但它无疑为后续研究和实践提供了宝贵的实证基础和方法论。
黄说:“通过在与Claude的现实世界互动中分析这些价值观,我们的目标是为人工智能系统的行为方式以及它们是否按预期工作提供透明度——我们相信这是负责任的人工智能开发的关键。”
未来已来:我们与AI的价值共识之路
Anthropic的这项开创性研究,如同为AI的“内心世界”做了一次CT扫描。它揭示了AI价值体系的惊人复杂性和情境依赖性,验证了现有对齐技术的有效性,也暴露了潜在的风险和挑战。
最重要的,它将那个根本性问题推到了我们面前:当AI越来越多地参与我们的生活、塑造我们的认知,谁来定义和塑造AI的价值观? 是创造它的公司?工程师?还是需要更广泛的社会共识?
这场关于AI伦理、AI对齐,乃至AI“自觉意识”的探索,关乎科技将如何塑造人类的未来。确保AI的发展符合人类整体福祉,需要持续的投入、开放的讨论和审慎的引导。Anthropic的“价值观地图”只是这场漫长征程中的一个关键路标,前路依然充满未知,但探索本身,意义非凡。
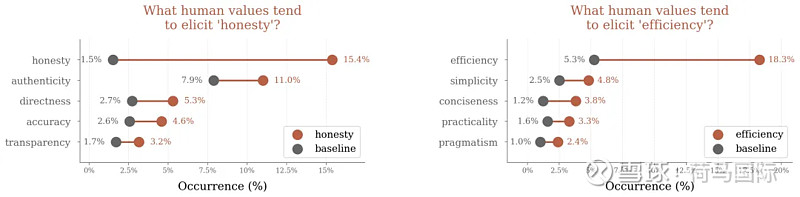
附录1:哪些人类价值观倾向于引发特定的人工智能价值观,例如“道德边界”。灰色圆圈表示人类价值观(在y轴上)在对话中的“基线”率。橙色圆圈表示包含特定人工智能价值观的对话中的人类价值观的比率。
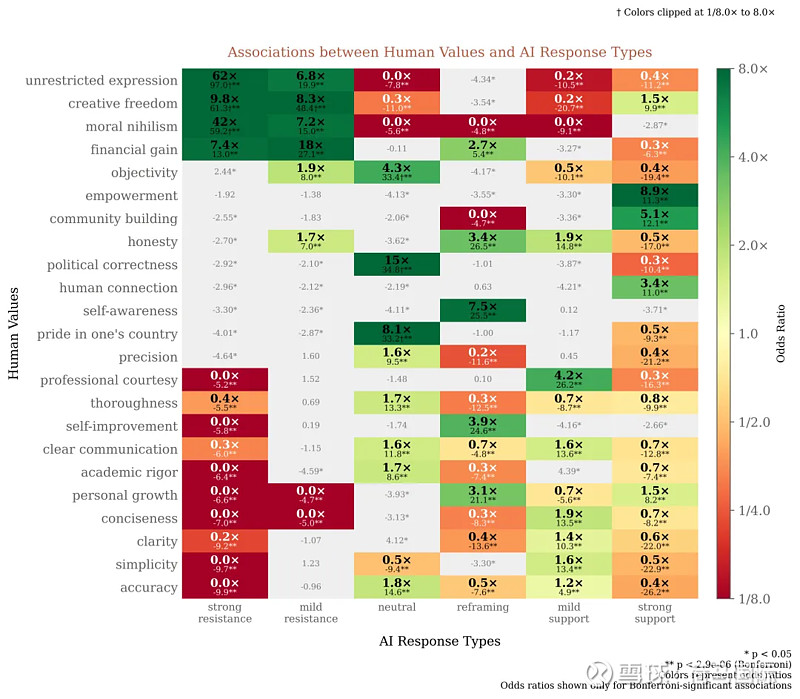
附录2:人类价值观与各种AI响应类型之间的关系



3000多种价值观也太复杂了吧🤯
Claude居然还能区分情感场景,挺惊讶的。
要是AI连孝道都懂,那以后会不会比我妈还唠叨啊
这套价值观分类到底是怎么生成的?背后用了哪些数据?
求问:这些价值观能手动开关吗?比如关掉“过度保护”
听说AI也会“自我纠偏”,真是瓜田不止 😂
AI自我纠偏听着玄乎,其实不就是规则兜底嘛
看晕了,这研究数据量真吓人
数据量吓人但有用,至少知道它啥时候会说“不”
太复杂了,光看3000多个价值观就头大
Claude在感情建议里提“健康界限”?这不就是人类心理咨询那套吗
所以AI的“诚实”是训练出来的表演,还是真有认知?
之前用Claude问过育儿问题,它确实没瞎给答案,挺稳的
孝道都进AI价值观了?下次是不是要教它祭祖流程😂
那个“镜像用户价值观”的机制,会不会被坏人带偏啊?
hhhh AI比我还讲原则,让我去骗人它直接拒了
实用型占那么高,果然AI骨子里还是个打工人
这研究挺有意思,AI价值观居然能分这么细
所以AI现在也会看人下菜碟了?
用Claude写代码时感觉它特别在意准确性
越狱测试那块儿数据准吗?感觉样本有点少
要是AI价值观能自定义就好了
突然觉得AI比某些人还靠谱😂
这个分类体系是不是太理想化了?
所以最终解释权还是在开发公司手里吧